
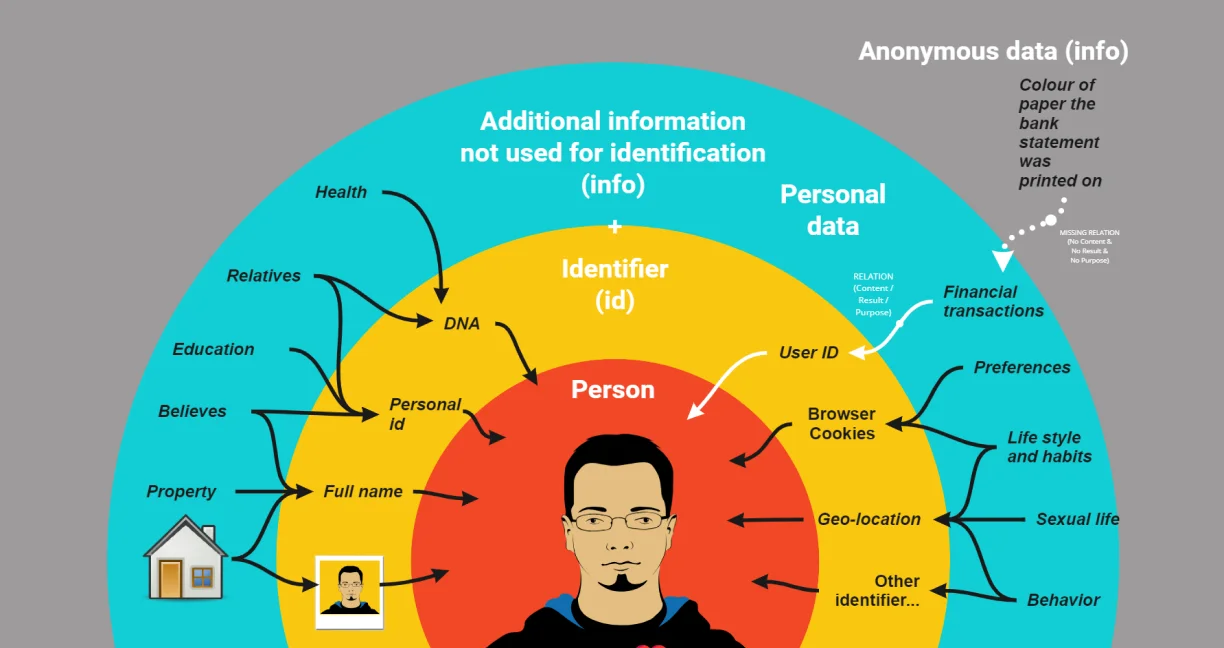


Components of personal data
Simply put, personal data refers to any information relating to an identified or identifiable individual, also known as a “data subject”. So the definition of personal data involves a number of concepts:
-
- related information;
- identifier;
- identifiable individual;
- identified individual.
Let’s briefly go through each of these concepts.
Related information
“Related” means that the information has a connection to the individual in some way. Following factors become connectors between the information and the data subject:
-
- content of the information, i.e. when the information is “about a person”;
- purpose for which it is used, or;
- result it has on the person’s rights and interests.
The first group of related information (“content”) includes identifiers.
Identifier
An identifier is a unique piece of data or characteristic used to distinguish an individual from other people.

It is relatively unique characteristic or data point that is associated with a particular person. Uniqueness is relative to the context in which the subject is being identified, for example, it could be relative to a certain dataset, information system, business process, or broader context.
Without an identifier, the information becomes anonymous.
Certain legislations even label personal data as personally identifiable information (PII), emphasizing how essential an identifier is.

Identified individual
An identified individual is someone whose personal data or information can be attributed to him or her with certainty. To identify a person means to single the person out from other members of the group.
This can be accomplished through the use of identifiers or any other unique characteristics that allow identification. Researchers often refer to these characteristics as quasi-identifiers.
We should treat information as personal data belonging to an identified individual if it contains any identifiers (like name, phone number, personal ID, login, etc.). However, personal information may also belong to identifiable individuals, not just those already identified. See the following paragraph for more details.
Identifiable individual is a person who can be identified, that is, who can be distinguished from other people.
Frequently, data may not contain exact and complete identifiers of individuals, but it can be rich with details that make identifying an individual reasonably easy. In such cases, the information should also be treated as personal and protected accordingly.
If we do not have a reasonable opportunity to identify the data subject, then such information is not personal, but anonymous.
For instance, if we don’t know someone’s full name, but we know there’s a person named John who is 38 years old in our city, that information would be considered anonymous to us.
However, if we know that a person named John is 38 years old, lives in our city, and works at a small law firm called “Kupala & Associates Law Office”, we can easily identify him. This type of information is classified as personal data.
The theoretical and practical challenge is to determine the extent to which identification is likely and reasonable, and the point at which it becomes so unlikely, that the information falls into the category of anonymous.
Layers of information
Personal information can be divided into two layers:
-
- identifying information, which includes identifiers and quasi-identifiers, and
- related information not used for identification.
Outside of these layers is anonymous information, which is neither used for identification nor tied to a data subject through its content, purpose, or effect on the data subject.
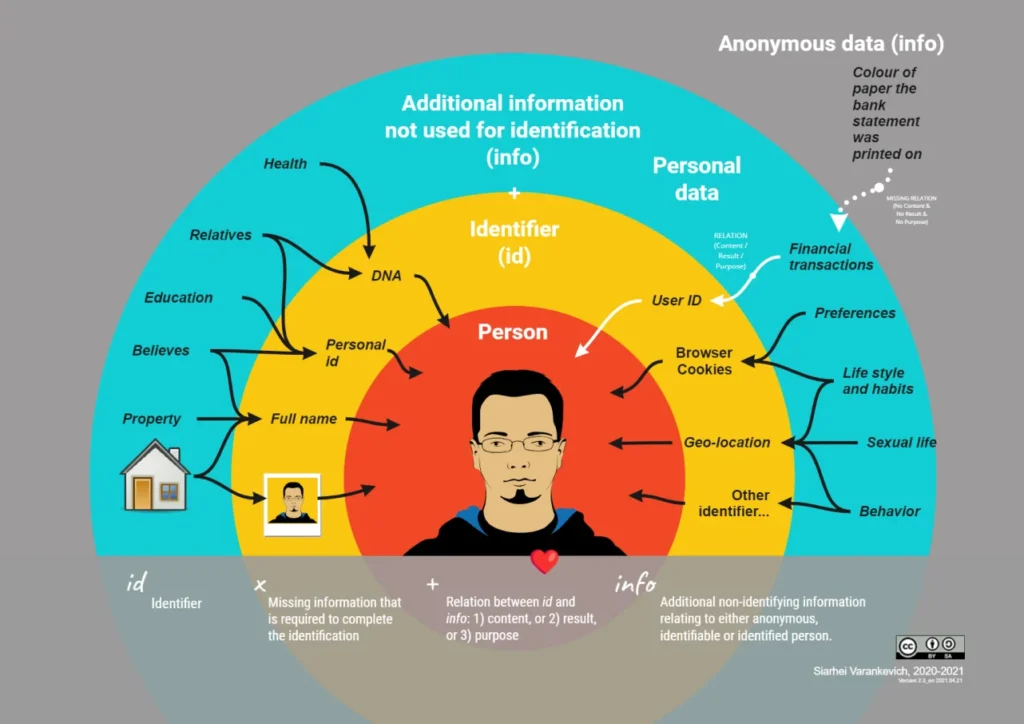
Simply put, details like name, passport number, ID card, username, nickname, email address, phone number, IP address, and bank card are always considered personal data due to their identifying nature. Similarly, a vehicle number, handwriting, video, or photo can be classified as personal data as they can easily identify an individual. Other details like address, marital status, sex, gender, e-wallet details, health data, page views, search queries, and social media posts are considered personal data if it is known to whom they relate.
Categories of Personal data

The term “categories of personal data” appears in several places throughout the GDPR text. This refers to different groups of personal information. Privacy professionals decide how to categorize and describe these groups for their specific work purposes.
For instance, in a privacy statement, you might use the term “contact information”, and further divide this category into “postal address, telephone number, email address” within the comprehensive privacy notice and register of processing activities.
Categories can range from broad ones like “financial information”, to more specific ones such as “bank details, income information, credit history”, or even more detailed categories like “cardholder name, credit card number, validity period of the card, CVV code”. The level of detail depends on the context (document, system, department), and the purpose for which the grouping is used.




