The building blocks of neural networks
Neural networks consist of interconnected units, sometimes called “neurons” (in the English-language literature, the term “nodes” is often used). These “neurons” serve as the fundamental computational units that process and transmit information throughout the network. Like the biological neurons in our brain, artificial “neurons” work together to solve complex tasks. Let us examine how they work through an example.
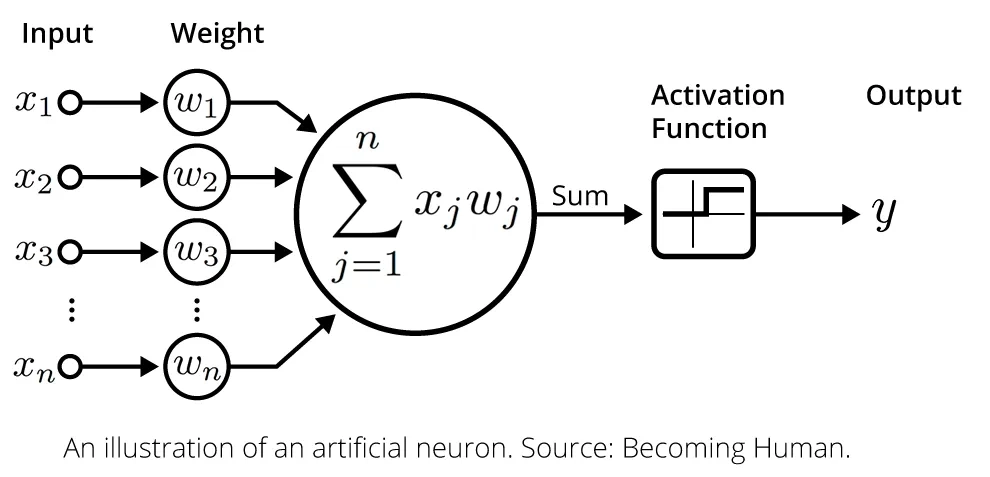
Example: Imagine that we have a “neuron” that tries to determine the price of one night in a hotel based on several factors, such as the distance to the city center, the hotel’s rating, and the number of stars. Each of these factors is an input to our neuron — that is, information it receives. Each input has its own weight, which represents the importance of that factor for the decision. For instance, if the neuron considers the rating to be the most important factor, it will be assigned a greater weight than the other inputs and will have a stronger effect on the hotel price than the other factors. Let us say the rating has a weight of 0.6, the distance — 0.3, and the number of stars — 0.4. In addition, our neuron has a bias, which can be thought of as a kind of sensitivity level of the neuron. If the bias is high, the “neuron” will be more inclined to make a positive decision at small input values. Conversely, a low bias means the neuron will activate only at more significant input values. In our example, the bias can be thought of as the minimum price below which the hotel cannot be rented. This price will be added to each output value. Now that we have weights and a bias, the “neuron” sums the products of weights and input values, adds the bias, and passes this sum to an activation function. So, if the total sum is below a certain threshold, the “neuron” may decide that the price cannot be determined and will output 0. In this way, our “neuron” analyzes various factors (input values), taking into account their importance (weights) and baseline values (bias), in order to make a decision about the hotel price.
Mathematically, the calculations performed by a neuron can be represented as follows:
Output = Activation function (sum of inputs, each multiplied by its weight + bias)
Layers: organizing neurons into functional units
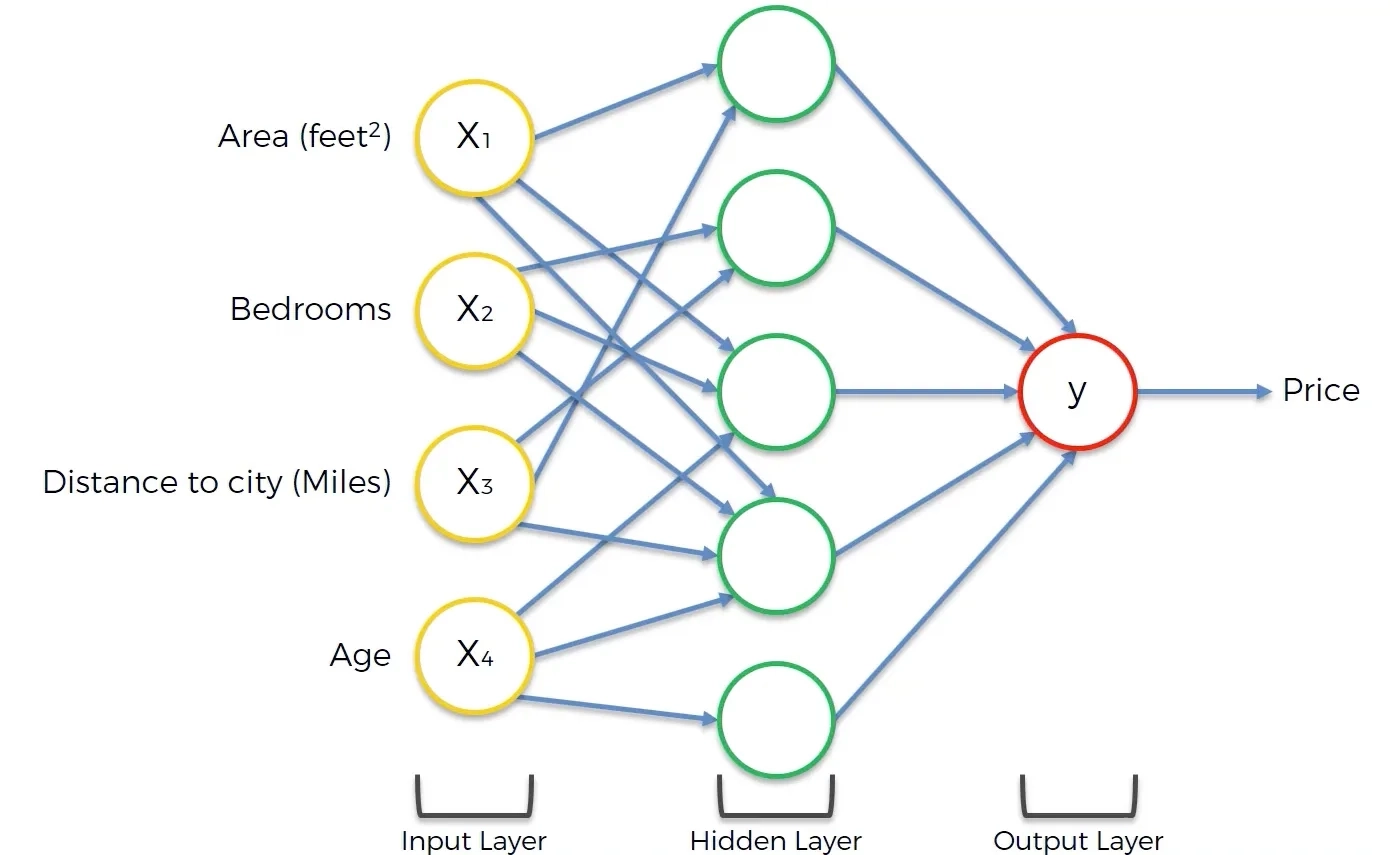
Each “neuron” passes its output value to the next, which makes its own inference based on the output of the previous one. For example, if the goal of our neural network were to decide whether it is worth building a hotel in a particular location, then the next neuron would use information about the approximate price per night to draw a conclusion about the hotel’s profitability. “Neurons” are combined into groups that analyze specific characteristics, and groups of “neurons” are combined into layers, each performing a specific task in the information-processing pipeline. There are three main types of layers in neural networks:
Input layer: This is the initial layer where the network receives external data. Each neuron in this layer represents a feature or attribute of the input data. Thus, if the neural network receives a photograph as input, the “neurons” in the input layer break it into pieces that will subsequently be analyzed.
Hidden layers: These are the layers between the input and output layers, where the actual computations take place. The number of hidden layers and neurons in them can vary, which allows neural networks to model complex relationships in the data.
Output layer: This is the final layer, which produces the network’s predictions or classifications based on the processed input data. The number of “neurons” in this layer usually corresponds to the number of possible outputs.
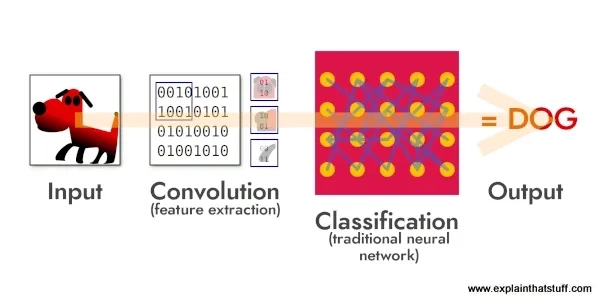
Convolutional layers (convolution layers) are often singled out as a separate type: when a photograph passes through a convolutional layer, something similar to scanning the image takes place. At this layer, the neural network looks for certain patterns or shapes — for example, edges, corners, or textures — that help it understand what is depicted in the picture. After the convolutional layer, the photograph is broken into pieces representing the detected objects, which will be smaller in size and easier to analyze.
In the illustration below, you can see an example of a neural network that analyzes hotel prices based on room area, number of bedrooms, distance to the city, and the client’s age (to account for senior discounts).
The journey of data through AI
Imagine a neural network tasked with analyzing your photograph and drawing conclusions about its content — for example, the gender of the person in the photograph, what they are wearing, and how old they are. As your photograph begins its journey through this neural network, it undergoes a series of complex computations.
Forward propagation
To visualize what the neural network “sees” and what it pays attention to, one can use a technique called feature visualization. This technique makes it possible to reconstruct images that maximally activate specific neurons within the neural network.
The feature visualization process begins with a random image or noise, which is then optimized to maximize the activation of a specific “neuron” or group of “neurons” in a particular layer of the network. This is achieved by altering the pixels of the image so that they activate the selected “neurons” as strongly as possible.
After several iterations of optimization, an image is produced that maximally stimulates the chosen “neurons“. This image can be interpreted as a visualization of what the neural network “sees” in the data.
To begin with, the neural network receives your photograph, which to it looks like a table, each cell of which contains a code denoting the color of a single pixel. For example, black has the code #000000. As the photograph moves through the network, it undergoes a series of transformations that gradually decode its features, nuances, and patterns.
Below you can see an illustration of how, at later layers, the neural network “sees” the characteristics of one fragment of the photograph. The value of the activation function for each output is shown on the side. Thus, the neural network “sees” that the selected fragment resembles a person’s neck or the lower part of a face.

Backpropagation: learning from mistakes
Since image-recognition neural networks are most often trained using “supervised learning“, when the photograph’s journey through the network culminates at the output layer, the network’s predictions are compared with the actual content of the photograph, and the discrepancy is analyzed. This is where backpropagation comes into play, allowing the network to learn from its mistakes and refine its understanding of the photograph.
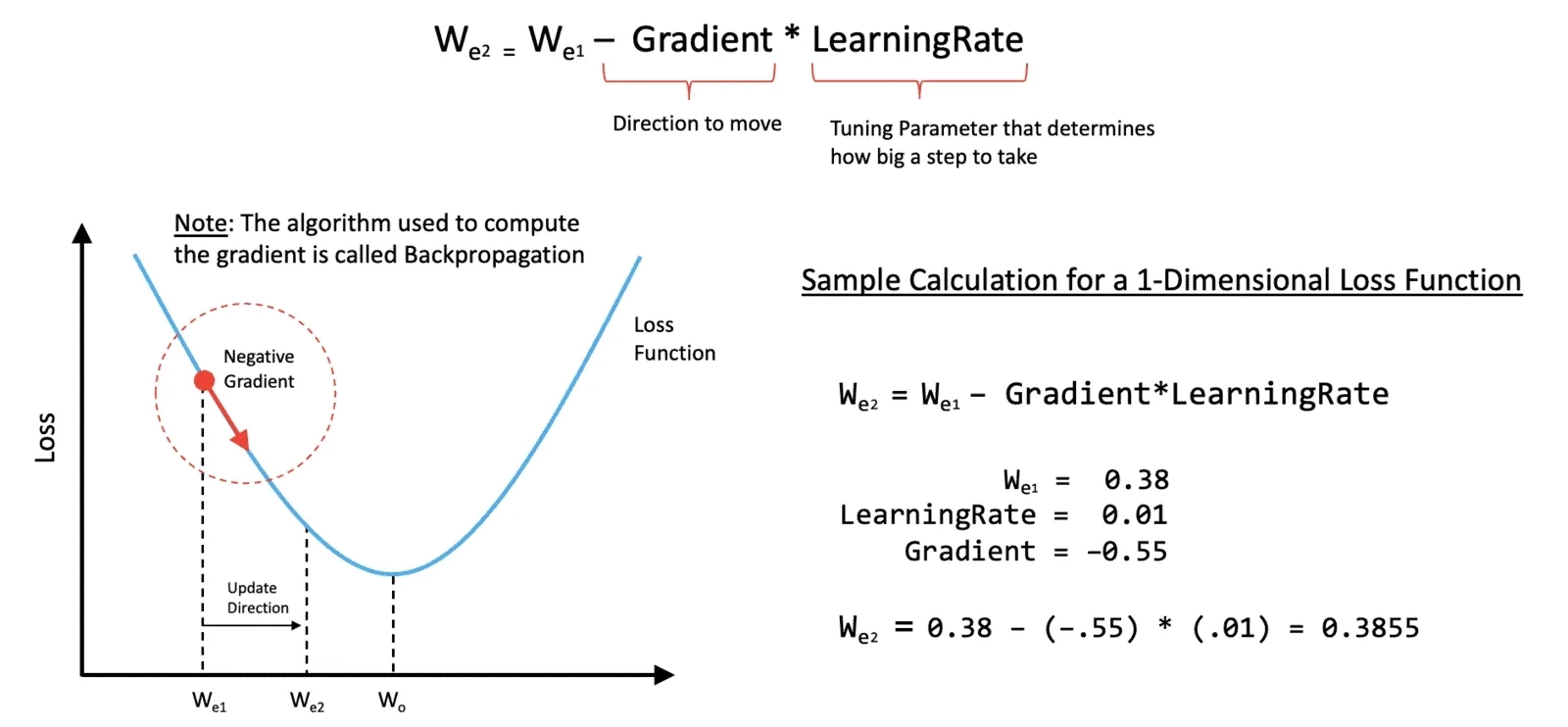
Computing gradients
Backpropagation involves the calculation of gradients by various methods, which represent the rate of change of the network’s error with respect to its weights and biases. In essence, this step determines the contribution of each parameter to the overall prediction error, so that it can subsequently be adjusted to come closer to the desired value.
Updating weights and biases
Armed with the gradients, the network updates its weights and biases using optimization algorithms such as gradient descent, steering them in the direction that minimizes errors. It is precisely this process that enables the network to learn.
Note: In this article, we will consider gradient descent in its classical form; however, it should be noted that when it comes to image analysis, the high dimensionality makes gradient descent in its original form infeasible, and therefore approximate methods that follow similar logic are used instead.
The graph below shows this process in more detail. The value W0 is the desired result of the computation. These are the values that the developer ultimately provides to the network, saying “With a probability of 100%, the photograph depicted a man”. Meanwhile, We1 is the result initially obtained by the network: “With a probability of 80%, the photograph depicts a woman”. Using gradient descent, the network adjusts its weights so as to approach W0. It calculates which factor influenced the error and changes its weight. For example, the network might initially have “decided” that all women have a pointed chin, and therefore this feature carried a large overall weight. After the network receives a photograph of a man with a pointed chin, it will reduce the weight of this feature so that it does not distort the result.
After updating the weights and recalculating, the network arrives at the value We2, which lies closer to the desired result: “With a probability of 60%, the photograph depicts a woman”.
The training process will then continue to repeat until the developer is satisfied with the network’s performance.
Diving deeper into the algorithm
When a photograph passes through a neural network, each successive layer, as a rule, analyzes more complex features.
For example, the first hidden layers may be responsible for recognizing basic image characteristics such as edges, textures, and colors. “Neurons” in the first layer may respond to vertical or horizontal lines in the image, while others may detect areas of a particular color.
As the image advances through the network, the intermediate layers begin to aggregate the basic characteristics detected in the previous layers in order to recognize more complex patterns. For example, neurons in these layers may begin to form combinations of edges to identify more complex textures, such as skin or hair.
The final layers are typically responsible for recognizing more abstract and complex concepts — such as the shape of a face and the position of the eyes and mouth — in order to make the final prediction as to whether the image contains the object the network has been trained to recognize, for example, a face.
Thus, in the illustration below, the leftmost layer analyzes pointwise characteristics of the image, attempting to determine the color and texture at a specific location of the photograph, while the rightmost generalizes the characteristics and attempts to recognize more general patterns.

But why does what the neural network “sees” differ so greatly from the original photograph?
At the later layers of a neural network, the images become less similar to the source photographs because at this stage of processing the network focuses on abstract and complex features and concepts that it has learned from the training data. Here is why this happens:
Pooling: Pooling layers reduce the size of the image while preserving only the important characteristics (for example, in order to determine whether a person is depicted in the photograph, the network may decide that the background is unimportant and “blur” it). As a result, the image becomes less detailed but retains its main features. One could say that this is a “generalized” version of the image, which helps simplify processing for the neural network without losing important information.
Abstraction: The neural network strives for abstraction, isolating the features that it considers important for distinguishing between classes of objects. This can lead to images becoming increasingly abstract and difficult to interpret for human perception. Which features it considers important depends largely on the data on which the neural network was trained.
For example, if all the men the network has “seen” were wearing black glasses, then the network will first of all learn to recognize black glasses in a photograph, while omitting other features such as face shape or facial hair.
In the end, although neural networks can be effective at recognizing and classifying images, their way of “seeing” the world may differ greatly from how a human does.